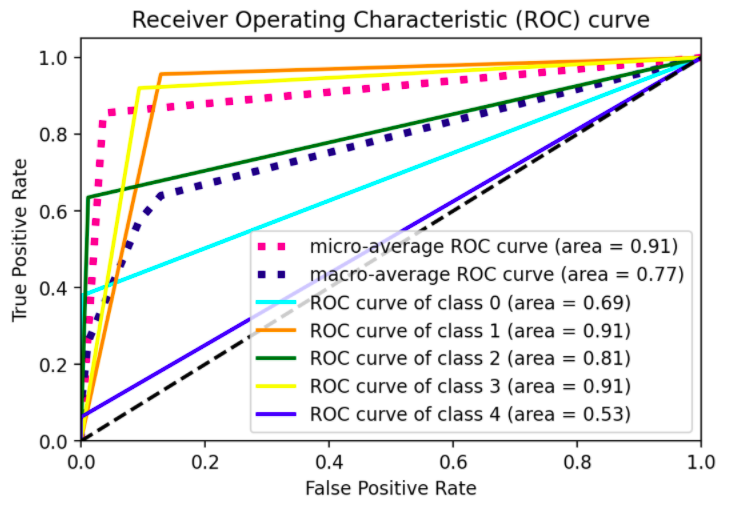
Я пытаюсь применить идею расширения sklearn ROC для мультиклассирования к моему набору данных. Моя кривая ROC для каждого класса выглядит как прямая линия, в отличие от примера sklearn, показывающего колебания кривой.
Ниже я привожу MWE, чтобы показать, что я имею в виду:
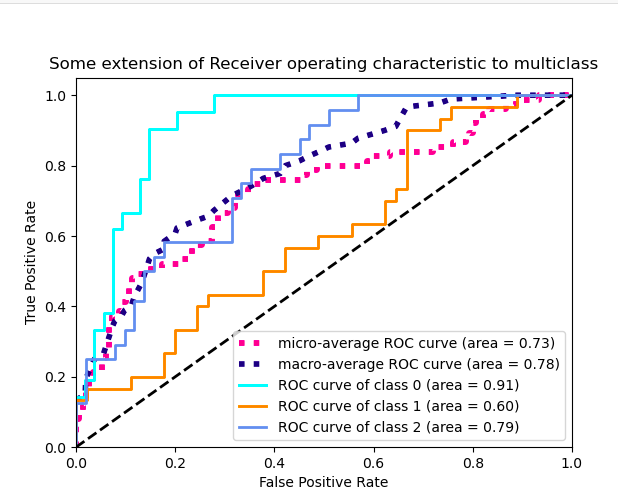
Вид прямой линии, изгибающейся один раз. Я хотел бы видеть производительность модели при разных пороговых значениях, а не только на одном, цифра похожа на иллюстрацию sklearn для трех классов, показанную ниже:
Я пытаюсь применить идею расширения sklearn ROC для мультиклассирования к моему набору данных. Моя кривая ROC для каждого класса выглядит как прямая линия, в отличие от примера sklearn, показывающего колебания кривой. Ниже я привожу MWE, чтобы показать, что я имею в виду: [code]# all imports import numpy as np import matplotlib.pyplot as plt from itertools import cycle from sklearn import svm, datasets from sklearn.metrics import roc_curve, auc from sklearn.model_selection import train_test_split from sklearn.preprocessing import label_binarize from sklearn.datasets import make_classification from sklearn.ensemble import RandomForestClassifier # dummy dataset X, y = make_classification(10000, n_classes=5, n_informative=10, weights=[.04, .4, .12, .5, .04]) train, test, ytrain, ytest = train_test_split(X, y, test_size=.3, random_state=42)
# random forest model model = RandomForestClassifier() model.fit(train, ytrain) yhat = model.predict(test) [/code] Затем следующая функция строит кривую ROC: [code]def plot_roc_curve(y_test, y_pred):
# Compute ROC curve and ROC area for each class fpr = dict() tpr = dict() roc_auc = dict() for i in range(n_classes): fpr[i], tpr[i], _ = roc_curve(y_test[:, i], y_pred[:, i]) roc_auc[i] = auc(fpr[i], tpr[i])
# Compute micro-average ROC curve and ROC area fpr["micro"], tpr["micro"], _ = roc_curve(y_test.ravel(), y_pred.ravel()) roc_auc["micro"] = auc(fpr["micro"], tpr["micro"])
# First aggregate all false positive rates all_fpr = np.unique(np.concatenate([fpr[i] for i in range(n_classes)]))
# Then interpolate all ROC curves at this points mean_tpr = np.zeros_like(all_fpr) for i in range(n_classes): mean_tpr += np.interp(all_fpr, fpr[i], tpr[i])
# Finally average it and compute AUC mean_tpr /= n_classes
colors = cycle(["aqua", "darkorange", "darkgreen", "yellow", "blue"]) for i, color in zip(range(n_classes), colors): plt.plot(fpr[i], tpr[i], color=color, lw=lw, label="ROC curve of class {0} (area = {1:0.2f})".format(i, roc_auc[i]),)
Вид прямой линии, изгибающейся один раз. Я хотел бы видеть производительность модели при разных пороговых значениях, а не только на одном, цифра похожа на иллюстрацию sklearn для трех классов, показанную ниже: [img]https://i.sstatic.net/4YYEt.png[/img]
Я работаю над проблемой бинарной классификации, где у меня есть ~ 30 функций ферментных субстратов для прогнозирования EC1 и EC2. Я использую XGBOOST с Optuna для настройки гиперпараметра. Тем не менее, я наблюдаю за несоответствием между значениями...
Я работаю над проблемой бинарной классификации, где у меня есть ~ 30 функций ферментных субстратов для прогнозирования EC1 и EC2. Я использую XGBOOST с Optuna для настройки гиперпараметра. Тем не менее, я наблюдаю за несоответствием между значениями...
Мне нужно определить, насколько хорошо разные модели классификации предсказывают значения. Для этого мне нужно построить кривую ROC, но я изо всех сил пытаюсь разработать подход.
Я включил весь свой код Python, а также ссылку на используемый мной...
У меня есть данные по 5000 наблюдений. Я разделил набор данных на две части: переменные ( X_train ) и помеченная цель ( y_train). Я использую pyod , потому что это самая популярная библиотека Python для обнаружения аномалий.
Я адаптирую модель к...
 Мобильная версия
Мобильная версия