 Мобильная версия
Мобильная версияКод: Выделить всё
df = pd.DataFrame(index=pd.Index(['1', '1', '2', '2'], name='from'), columns=['to'], data= ['2', '2', '4', '5'])
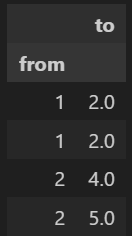
Теперь я хотел бы вычислить матрицу, содержащую процент переходов каждого значения в индексе «от» к каждому значению в столбце «до», который известен как матрица перехода. Я могу добиться этого, сначала создав пустую матрицу перехода, а затем заполнив ее процентами с помощью цикла for:
Код: Выделить всё
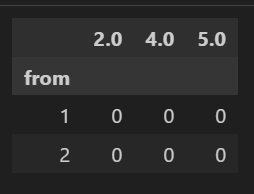
#Create an empty matrix to populate later (using sparse dtype to save memory):
matrix = pd.DataFrame(index=df.index.unique(), columns=df.to.unique(), data=0, dtype=pd.SparseDtype(dtype=np.float16, fill_value=0))
Код: Выделить всё
for i in range(len(df)):
from_, to = df.index[i], df.to.iloc[i]
matrix[to] = matrix[to].sparse.to_dense() # Convert to dense format because sparse dtype does not allow value assignment with .loc in the next line:
matrix.loc[from_, to] += 1 # Do a normal insertion with .loc[]
matrix[to] = matrix[to].astype(pd.SparseDtype(dtype=np.float16, fill_value=0)) # Back to the original sparse format
matrix = (matrix.div(matrix.sum(axis=1), axis=0)*100) # converting counts to percentages
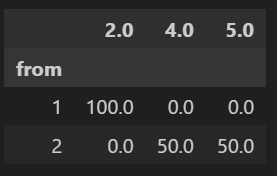
Это работает. Например, индекс «1» переходил в «2» только в 100% случаев, а индекс «2» переходил в «4» в 50% случаев и в «5» в остальных 50% случаев, что может необходимо проверить в df.
Проблема: Фактический размер матрицы составляет около 500 х 500 КБ, и завершение цикла for занимает очень много времени. Итак, существует ли векторизованный или другой эффективный способ вычисления матрицы из df
Примечание: я бы получил MemoryError, не используя весь Sparse dtype, даже с dtype =float16 в pd.DataFrame(), поэтому я предпочитаю оставить это, если это возможно. Кроме того, если это имеет значение, очевидно, что эти проценты всегда будут иметь диапазон от 0 до 100.
Подробнее здесь: https://stackoverflow.com/questions/792 ... fficiently