 Мобильная версия
Мобильная версияЯ пытался удалить/обрезать таблицу личной информации из этого образца sample_pdf со всех страниц, найдя layout значения таблицы. Я новичок в pdfplumber и не уверен, что это правильный подход, но ниже приведен код, который я пробовал, и я не могу получить значения макета таблицы, даже если я могу получить красный цвет ящик на столе с помощью pdfplumber.
Код, который я пробовал:
sample_data = []
sample_path = r"local_path_file"
with pdfplumber.open(sample_path) as pdf:
pages = pdf.pages
for p in pages:
sample_data.append(p.extract_tables())
print(sample_data)
pages[0].to_image()
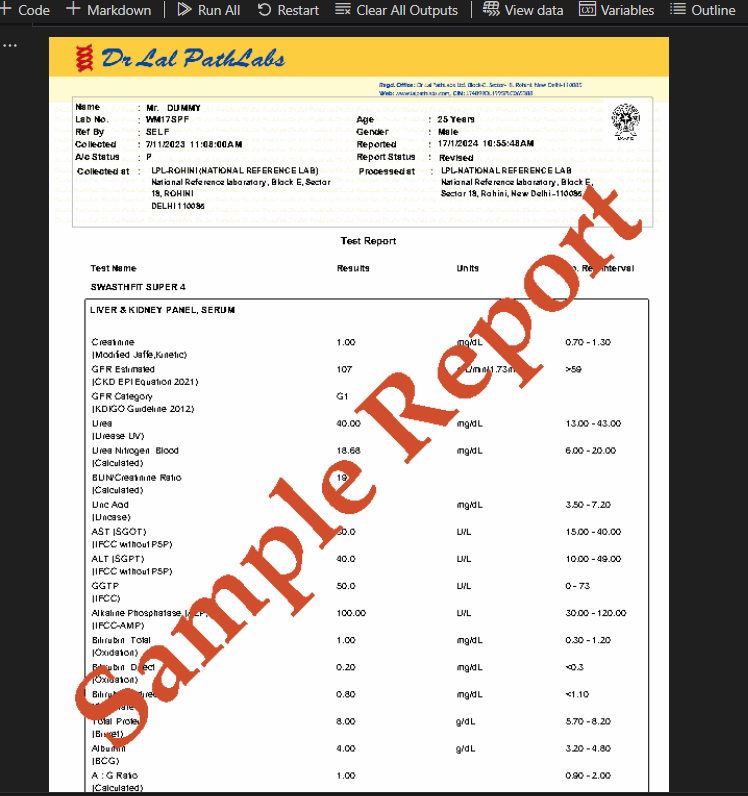
Я можно идентифицировать первую таблицу из нее, используя приведенный ниже код
pages[0].to_image().debug_tablefinder()
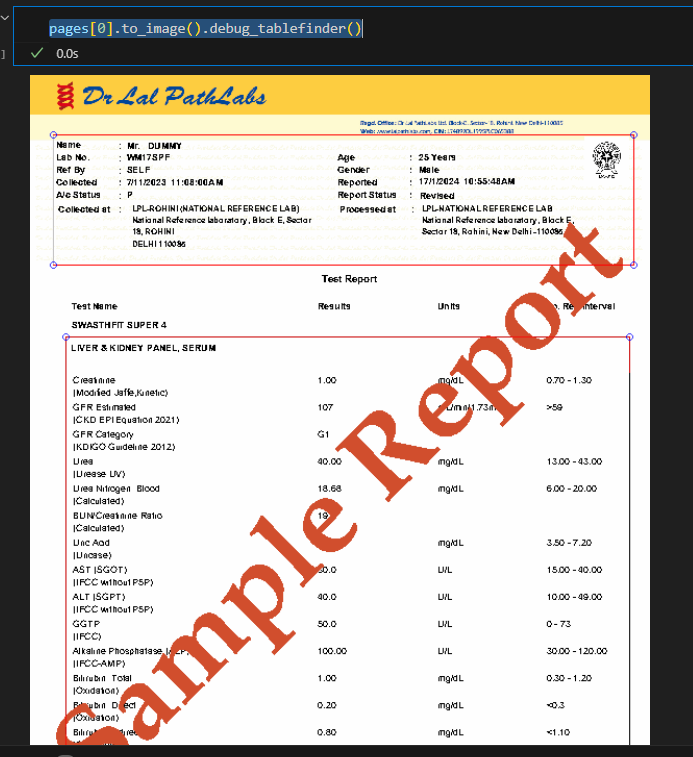
Теперь, когда Я пытаюсь извлечь таблицы с помощью приведенного ниже кода, но ничего не получаю
with pdfplumber.open(sample_path) as pdf:
pages = pdf.pages[0]
print(pages.extract_tables())
выход: []
Обновить
При работе с этим конкретным примером PDF-файла возникла проблема, но когда я использовал аналогичный отчет в формате PDF, мне удалось обрезать его на основе таких границ:pages[0].find_tables()[0].bbox
выход:
(25.19059366666667, 125.0, 569.773065, 269.64727650000003)
Это показывает ту часть, от которой я хочу избавиться:
p0.crop((25.19059366666667, 125.0, 569.773065, 269.64727650000003)).to_image().debug_tablefinder()
Ниже берет y0 = 269,64, где заканчивается верхняя таблица, почти до низа страницы y1 = 840 и от самой левой части x0 = 0 страницы почти до правого края x1 = 590:
p0.crop((0, 269.0, 590, 840)).to_image()
При работе с этим конкретным примером PDF-файла возникла проблема, но когда я использовал аналогичный отчет в формате PDF, мне удалось обрезать это основано на границах.
Вот что я использовал:
pages[0].find_tables()[0].bbox
выход:
(25.19059366666667, 125.0, 569.773065, 269.64727650000003)
# this shows the part that I want to get rid off
p0.crop((25.19059366666667, 125.0, 569.773065, 269.64727650000003)).to_image().debug_tablefinder()
# below taking y0 value from where top table ends (269.64) to almost bottom of page 840
# x0 from leftmost part (0) of page and x1 as (590) to almost right end of page
p0.crop((0, 269.0, 590, 840)).to_image()
Подробнее здесь: https://stackoverflow.com/questions/792 ... pdfplumber