 Мобильная версия
Мобильная версияЯ пытался удалить/обрезать таблицу личной информации из этого образца sample_pdf со всех страниц, найдя layout значения таблицы. Я новичок в pdfplumber и не уверен, что это правильный подход, но ниже приведен код, который я пробовал, и я не могу получить значения макета таблицы, даже если я могу получить красный цвет ящик на столе с помощью pdfplumber.
Код, который я пробовал:
Код: Выделить всё
sample_data = []
sample_path = r"local_path_file"
with pdfplumber.open(sample_path) as pdf:
pages = pdf.pages
for p in pages:
sample_data.append(p.extract_tables())
print(sample_data)
Код: Выделить всё
pages[0].to_image()
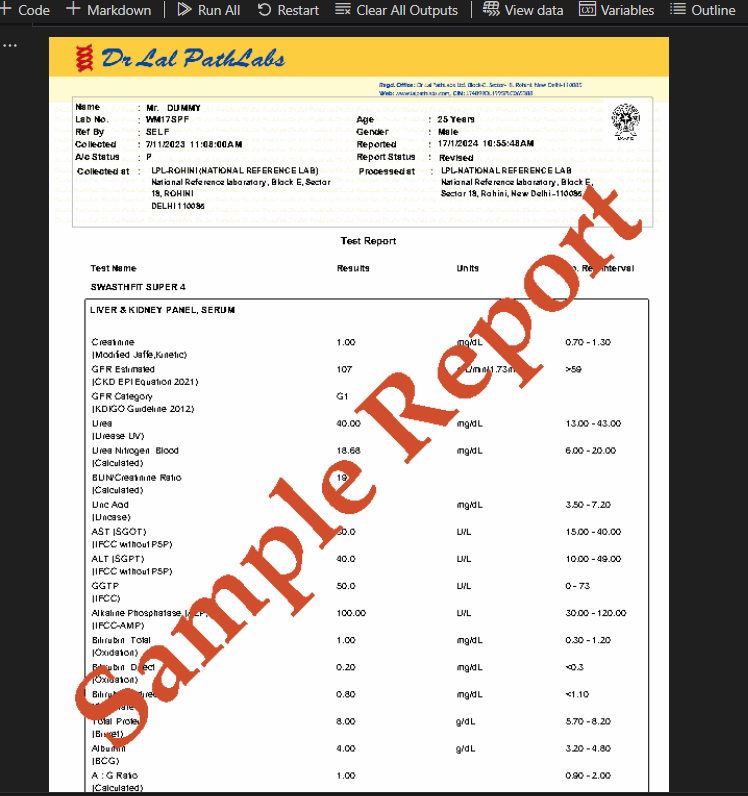
Я можно идентифицировать первую таблицу из нее, используя приведенный ниже код
Код: Выделить всё
pages[0].to_image().debug_tablefinder()
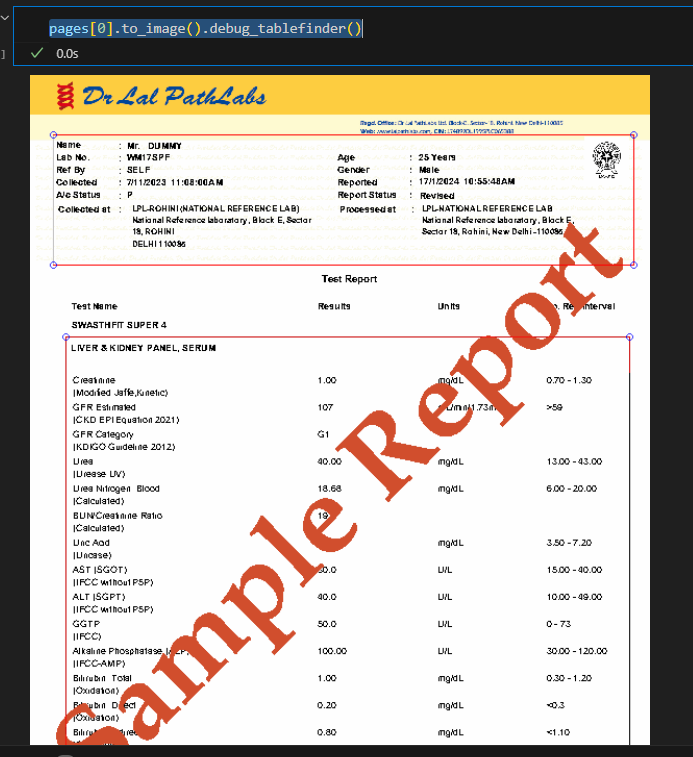
Теперь, когда Я пытаюсь извлечь таблицы с помощью приведенного ниже кода, но ничего не получаю
Код: Выделить всё
with pdfplumber.open(sample_path) as pdf:
pages = pdf.pages[0]
print(pages.extract_tables())
Буду очень признателен за любую помощь.
Подробнее здесь: https://stackoverflow.com/questions/792 ... ion-issues